.jpg)
앤쓰로픽 코파일럿 코워크 선보인 마이크로소프트···AI 파트너 바꿔가며 오피스 왕좌 지킨다
by
2026년 3월 11일
[테크수다 기자 도안구 eyeball@techsuda.com] 마이크로소프트가 추론 칩 ‘마이아 200(Maia 200)’을 공개했다. 마이아 200은 마이크로소프트 애저(Azure) 환경에서 AI 모델을 더욱 빠르고 경제적으로 구동할 수 있도록 지원하며 차세대 AI 인프라의 핵심 역할을 수행할 예정이다.
스콧 거스리(Scott Guthrie) 마이크로소프트 클라우드 및 AI 부문 수석 부사장은 AI 특화 데이터센터를 ‘토큰 팩토리’로 정의한다. 그는 "Maia 같은 전용 실리콘은 와트·달러당 토큰 생산성을 극대화하는 전략의 핵심"이라고 강조했다.
마이아 200은 TSMC의 3나노미터(nm) 공정을 기반으로 고성능 AI 추론에 최적화된 구조를 갖췄다. 특히 초당 7TB 대역폭의 216GB HBM3e 메모리 시스템과 네이티브 FP8/FP4 텐서 코어, 그리고 데이터 이동 엔진을 유기적으로 결합해 거대 모델에 최적화된 추론 성능을 제공하는 것이 특징이다.
실제 연산 성능에서도 주목할 만한 지표를 기록했다. 마이아 200은 4비트 정밀도(FP4) 기준 3세대 아마존 트레이니움(Amazon Trainium) 대비 3배 높은 처리량을 기록했으며, 8비트 정밀도(FP8)에서도 구글의 7세대 TPU를 상회한다. 마이크로소프트는 이러한 기술력을 바탕으로 자사 인벤토리 내 최신 하드웨어 대비 달러당 성능(Performance per dollar)을 30% 개선하며 효율적인 추론 시스템을 구축했다.
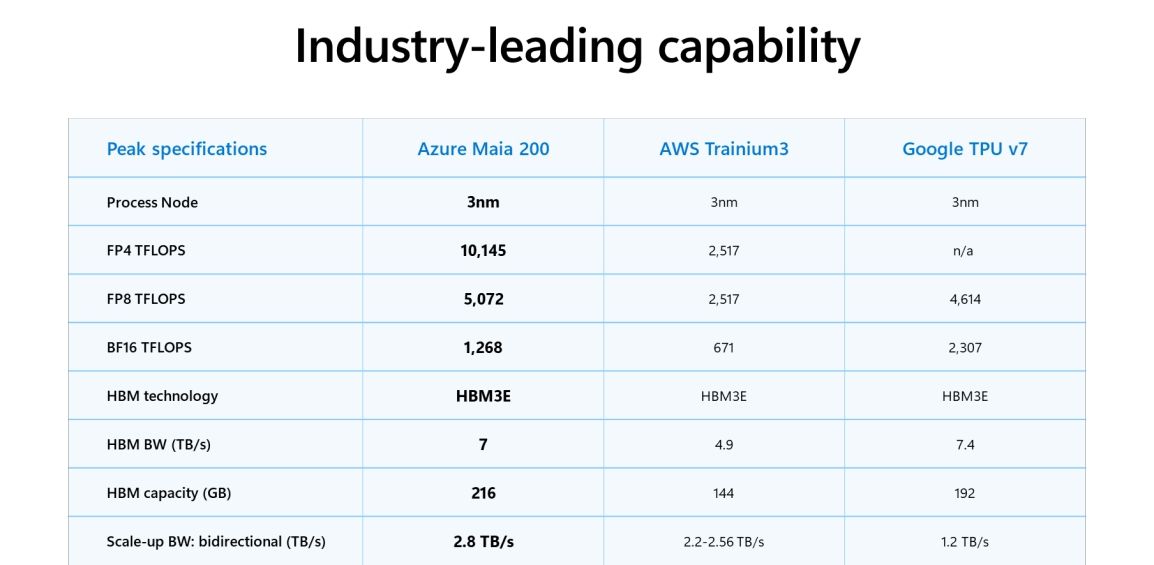
마이크로소프트의 이기종AI 인프라에서 핵심 역할을 수행할 마이아 200은 오픈AI의 최신 GPT-5.2 모델을 비롯한 다양한 모델을 지원한다. 이로써 마이크로소프트 파운드리(Microsoft Foundry)와 마이크로소프트 365 코파일럿(Microsoft 365 Copilot)의 가격 대비 성능 효율을 제공한다.
마이크로소프트 슈퍼인텔리전스(Microsoft Superintelligence)팀은 차세대 사내 모델 개선을 위한 합성 데이터 생성 및 강화 학습에 마이아 200을 투입할 계획이다. 해당 칩은 고품질 도메인 특정 데이터의 생성 및 필터링 속도를 가속화해 후속 학습에 정교한 신호를 공급하는 중추적인 역할을 맡게 된다.
마이아 200은 아이오와주 디모인(Des Moines) 인근 미국 중부(US Central) 데이터 센터 지역을 시작으로 배포가 진행된다. 향후 애리조나주 피닉스(Phoenix) 인근 US West 3 지역 등으로 확대될 예정이다.
AI 추론 최적화를 위한 정밀 설계와 시스템 아키텍처
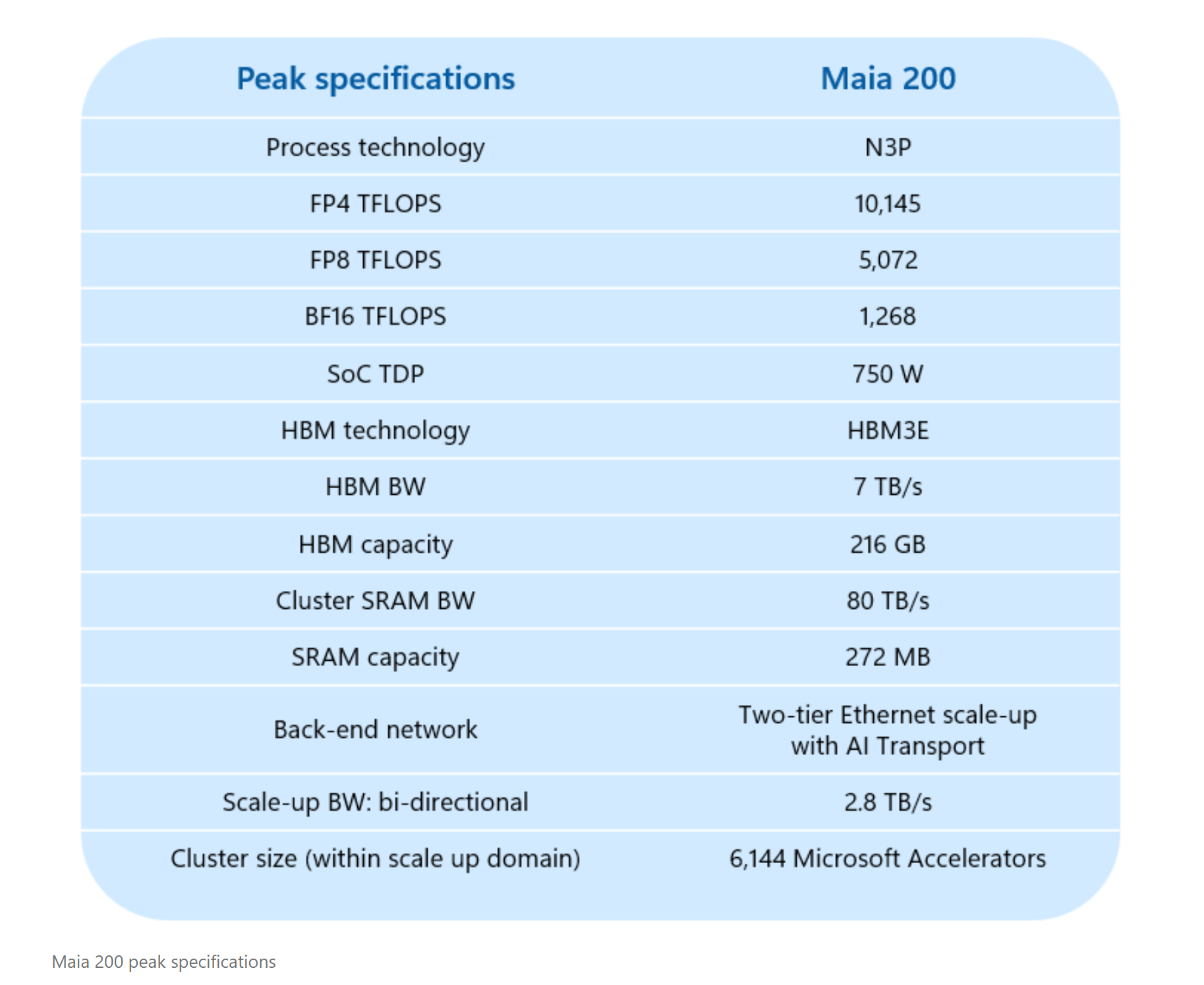
마이아 200은 1,400억 개 이상의 트랜지스터를 탑재해 대규모 AI 워크로드에 특화된 설계를 갖췄다. 750W SoC TDP(설계 전력) 범위 내에서 각 칩은 FP4 기준 10 PFLOPS 초과, FP8 기준 5 PFLOPS 초과 성능을 제공한다. 이러한 연산 성능은 대규모 모델 구동을 원활히 지원하며, 향후 등장할 차세대 모델까지 대응 가능한 수준의 성능 여유를 확보한다. 또한 데이터 공급 병목 현상 해결을 위해 메모리 하위 시스템을 전면 재설계해 토큰 처리량을 최적화했다.
이러한 성능은 대규모 클러스터 환경에서도 일관되게 구현된다. 마이크로소프트는 표준 이더넷 기반의 새로운 2계층 스케일업 네트워크를 도입했으며, 맞춤형 전송 계층과 통합 NIC를 통해 독점적인 패브릭 없이도 성능과 신뢰성, 비용 이점을 확보했다. 각 가속기는 초당 2.8TB의 양방향 전용 스케일업 대역폭을 지원하며, 이는 최대 6,144개의 가속기를 연결하는 대규모 클러스터 전체에서 일관된 성능을 유지하고 애저 인프라의 전력 소모와 전체 소유 비용(TCO)을 절감하는 기반이 된다.
시스템 효율은 개별 단위인 트레이(tray)와 랙(rack) 수준의 정밀한 연결 구조를 통해 구현된다. 하나의 트레이 내부에 탑재된 4개의 가속기를 직접 연결해 내부 통신 효율을 높였으며, 동일한 통신 프로토콜을 사용해 랙 단위까지 원활하게 확장할 수 있도록 설계했다. 이러한 통합 네트워킹 환경은 프로그래밍을 단순화하고 워크로드의 유연성을 높여 시스템 운영 효율을 강화한다.
민첩한 개발 프로세스로 인프라 혁신 주기 단축

마이크로소프트 실리콘 개발 프로그램은 칩 출시 전 시스템 전반을 검증하는 엔드투엔드 방식을 원칙으로 한다. 설계 초기부터 LLM의 연산 및 통신 패턴을 모델링하는 프리 실리콘 환경을 구축해, 실제 칩 제작 전 이미 실리콘과 네트워킹, 시스템 소프트웨어를 하나의 체계로 최적화했다.
데이터센터 투입 준비도 설계 단계부터 병행했다. 백엔드 네트워크와 2세대 액체 냉각 시스템 등 복잡한 요소를 조기 검증하고 애저 제어 플레인)과 네이티브로 통합했다. 그 결과 마이아 200은 첫 부품 입고 수일 만에 실제 모델 구동에 성공했으며, 칩 입고부터 데이터 센터 배치까지의 기간을 기존 대비 절반 이하로 단축했다. 칩부터 소프트웨어, 데이터 센터를 아우르는 엔드투엔드 방식은 자원 활용률을 높이고 클라우드 규모에서의 비용 및 전력 효율을 지속적으로 개선한다.
마이크로소프트는 대규모 AI 시대가 본격화됨에 따라 인프라가 기술적 가능성을 결정짓는 핵심 요소가 될 것으로 내다보고 있다. 마이아 가속기 프로그램은 다세대 로드맵을 기반으로 설계됐으며, 향후 지속적인 혁신을 통해 새로운 벤치마크를 제시하고 핵심 AI 워크로드에 최적화된 성능과 효율성을 제공할 예정이다.
한편, 마이크로소프트는 학계와 개발자, 프론티어 AI 연구소 및 오픈소스 프로젝트 기여자들이 모델과 워크로드를 조기에 최적화할 수 있도록 ‘마이아 200 SDK’ 프리뷰를 공개했다. SDK는 Triton 컴파일러, 파이토치(PyTorch) 지원, NPL 프로그래밍을 포함하며, 특히 마이아 시뮬레이터와 비용 계산기를 통해 개발 초기 단계부터 운영 효율을 정밀하게 최적화하도록 돕는다. 마이아 200에 대한 보다 자세한 정보는 공식 웹사이트에서 확인 가능하다.
[테크수다 기자 도안구 eyeball@techsuda.com]

테크가 전 산업 영역에 스며드는 소식에 관심이 많다. 1999년 정보시대 PCWEEK 테크 전문지 기자로 입문한 후 월간 텔레닷컴, 인터넷 미디어 블로터닷넷 창간 멤버로 활동했다. 개발자 잡지 마이크로소프트웨어 편집장을 거쳐 테크수다를 창간해 지금까지 활동하고 있다. 태블릿을 가지고 얼굴이 꽉 찬 방송, 스마트폰을 활용한 현장 라이브를 한국 최초로 진행했다.


