.jpg)
AI 시대 사이버보안 대연합 출범···앤쓰로픽, '글래스윙 프로젝트'로 AWS·애플·구글·MS 한 데 묶다
by
2026년 4월 9일

[테크수다 기자 도안구 eyeball@techsuda.com] LG AI연구원이 9일 텍스트와 이미지를 동시에 이해하고 추론하는 멀티모달 AI 모델 '엑사원(EXAONE) 4.5'를 공개했다. 이 모델은 자체 개발한 비전 인코더와 거대언어모델(LLM)을 하나의 구조로 통합한 비전-언어 모델(VLM)로, AI 시각 능력 평가 지표 13개 평균에서 오픈AI GPT-5 mini와 중국 알리바바 Qwen3-VL을 상회하는 성능을 기록했다. 330억 개(33B) 파라미터 규모임에도 독자 파운데이션 모델 'K-엑사원' 대비 약 7분의 1 크기로 동등한 추론 성능을 달성했다.
주요 내용:
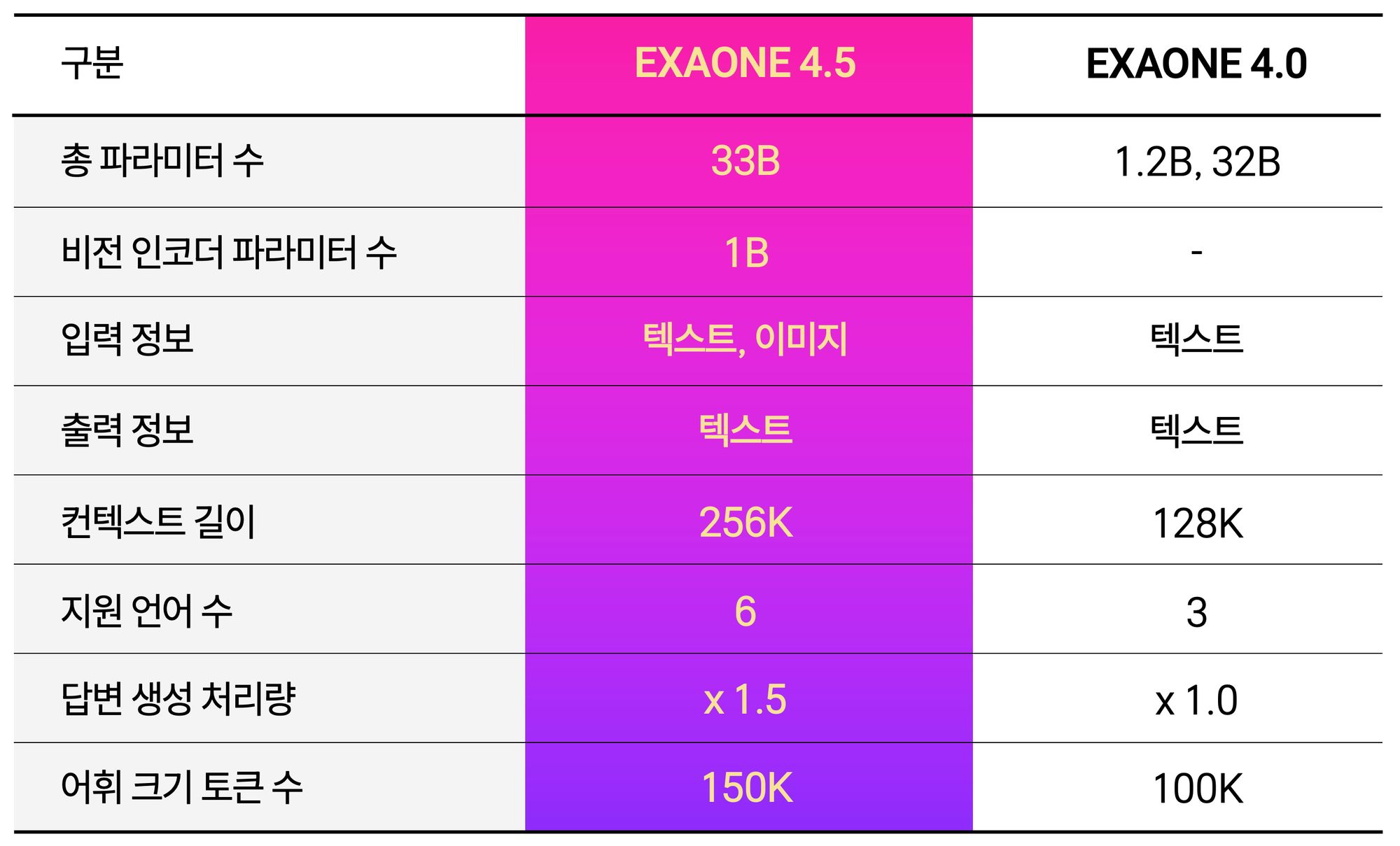
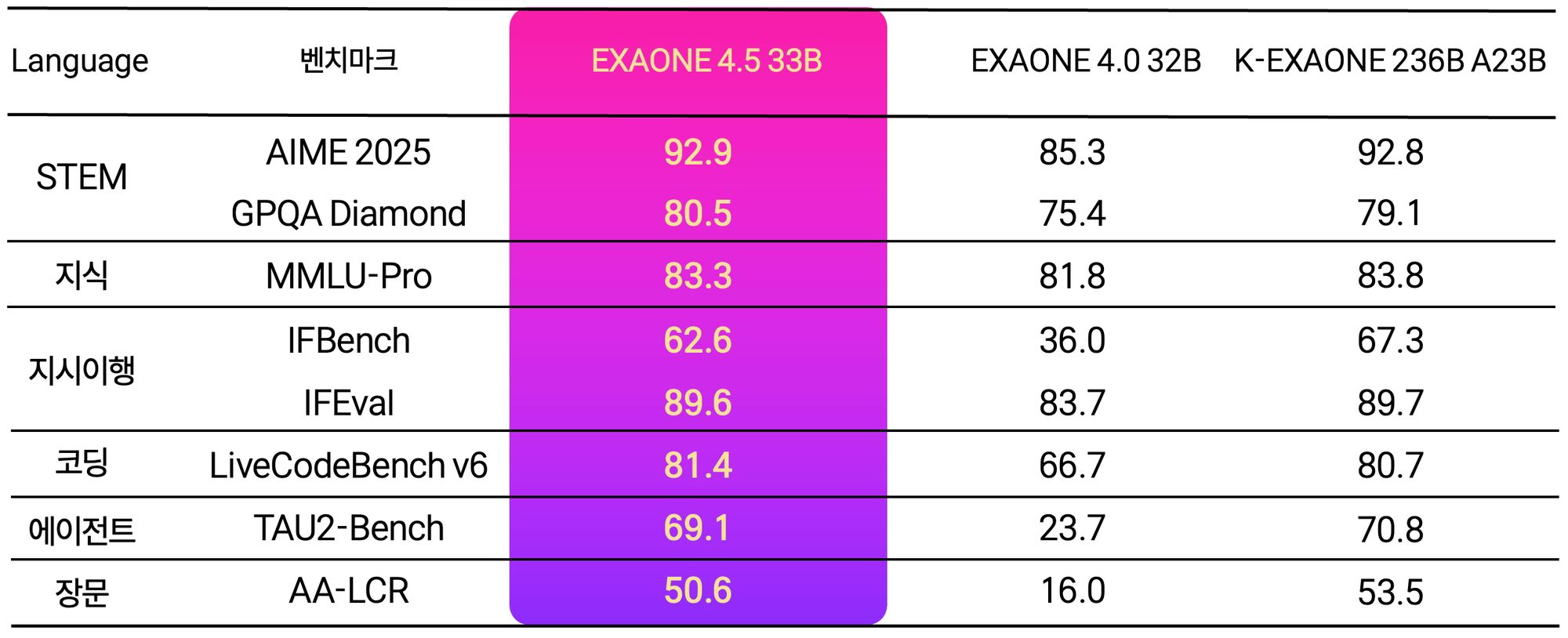
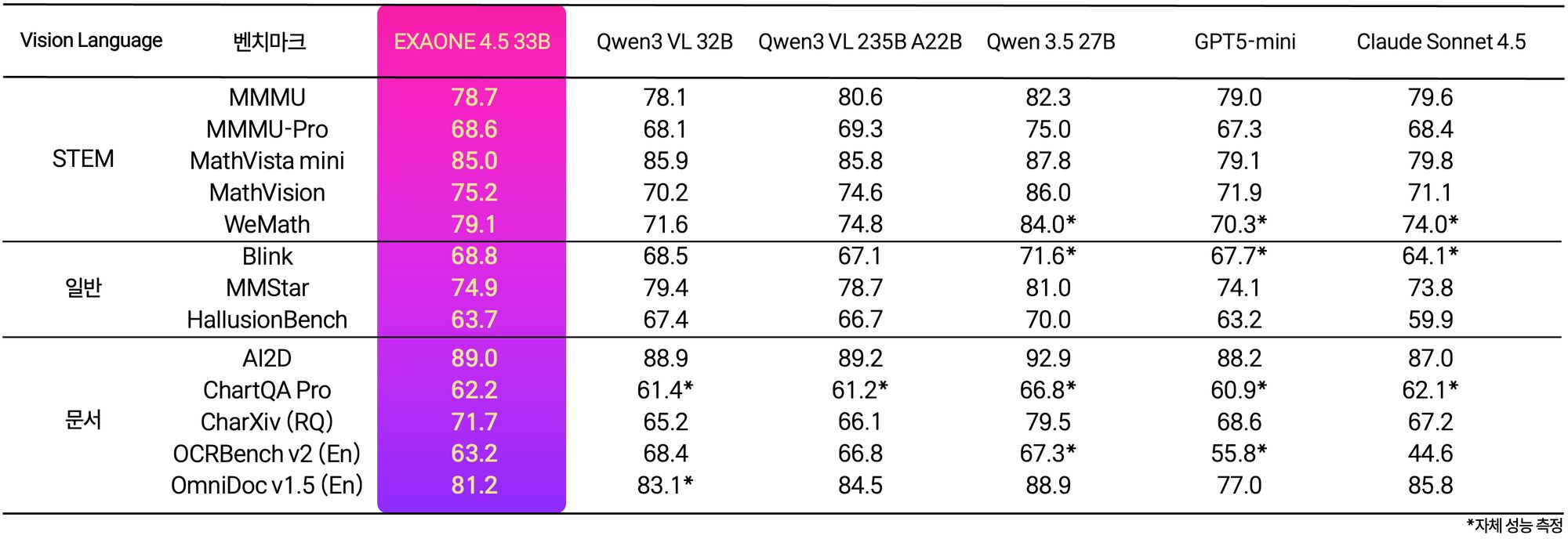
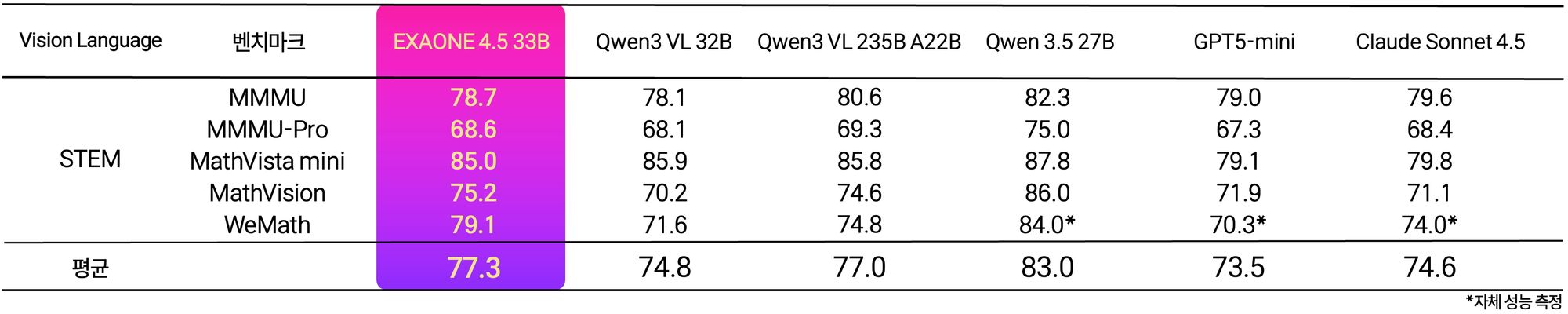
'엑사원 4.5'는 계약서, 기술 도면, 재무제표 등 산업 현장에서 실제로 다루는 복합 문서를 정확히 읽고 추론하는 능력에 강점이 있다. STEM 성능 평가 5개 지표 평균 77.3점으로 GPT-5 mini(73.5점), 클로드 소넷 4.5(74.6점), Qwen3 235B(77.0점)를 모두 앞섰으며, 복합 차트 분석 평가 ChartQA Pro에서는 62.2점을 기록해 동급 모델 대비 글로벌 경쟁력을 입증했다. 공식 지원 언어도 한국어·영어에서 스페인어, 독일어, 일본어, 베트남어로 확장됐으며, 자체 개발한 하이브리드 어텐션 구조와 멀티 토큰 예측 기반 고속 추론 기술을 적용해 효율성과 성능을 동시에 달성했다는 설명이다.
LG AI연구원은 이번 모델을 독자 AI 파운데이션 모델 'K-엑사원'의 모달리티 확장을 위한 기술적 토대로 제시했다. 오는 8월 프로젝트 3차수 진출이 확정되면 본격적인 멀티모달 확장에 나서고, 궁극적으로 물리적 세계를 이해하는 피지컬 인텔리전스 실현을 목표로 한다. LG AI연구원은 또한 동북아역사재단과의 협업을 통해 한국의 역사·문화·사회적 맥락을 깊이 이해하는 AI로의 진화도 병행 추진 중이다.
이진식 LG AI연구원 엑사원랩장은 "엑사원 4.5는 LG AI가 텍스트를 넘어 시각 정보까지 이해하는 멀티모달 시대로 진입했음을 보여주는 모델"이라며 "음성과 영상, 물리 환경까지 AI의 이해 범위를 확장해 산업 현장에서 실질적으로 판단하고 행동하는 AI를 만들어가겠다"고 밝혔다.
김명신 LG AI연구원 신뢰안전사무국 총괄은 "엑사원은 자체 설계한 AI 위험 분류체계(K-AUT)를 기반으로 풍부한 표현력과 신뢰성을 동시에 확보한 AI로 진화해 나갈 것"이라고 강조했다.
엑사원 4.5, 이런 점이 궁금하셨나요?
Q: GPT-5 mini보다 성능이 높다는 근거는 무엇인가요?
A: LG AI연구원은 STEM 성능 5개 지표, 일반 시각 이해 3개 지표, 문서 이해 및 추론 5개 지표 등 총 13개 AI 시각 능력 평가 벤치마크를 사용했습니다. 이 13개 지표 평균 점수에서 엑사원 4.5는 GPT-5 mini, 앤트로픽 Claude Sonnet 4.5, 중국 Qwen3-VL을 모두 상회했습니다.
Q: 오픈 웨이트 공개란 무엇이며, 누구나 사용할 수 있나요?
A: 오픈 웨이트란 AI 모델의 학습된 파라미터(가중치)를 외부에 공개하는 것으로, 연구자와 개발자가 이를 기반으로 자유롭게 활용할 수 있습니다. 엑사원 4.5는 허깅페이스(Hugging Face)에 공개됐으며, 연구·학술·교육 목적에 한해 누구나 이용 가능합니다. 상업적 활용은 별도 이용약관을 따릅니다.
Q: 피지컬 인텔리전스란 무엇이며 엑사원과 어떤 관련이 있나요?
A: 피지컬 인텔리전스(Physical Intelligence)는 AI가 가상 환경을 넘어 물리적 세계를 인식·판단해 로봇 등 실물 기기에서 행동할 수 있는 능력을 의미합니다. LG AI연구원은 엑사원을 텍스트→멀티모달→피지컬 인텔리전스 순으로 단계적으로 발전시키는 로드맵을 추진 중이며, 엑사원 4.5는 그 첫 번째 관문인 멀티모달 확장의 기술적 토대입니다.
LG AI Research Lab Unveils EXAONE 4.5 Multimodal AI, Outperforming OpenAI GPT-5 Mini in Key Benchmarks
SEOUL, April 9 — LG AI Research Lab on Thursday unveiled EXAONE 4.5, a vision-language model capable of simultaneously processing and reasoning over both text and images, marking the company's formal entry into the multimodal AI era. The model integrates a proprietary vision encoder with a large language model into a unified architecture, surpassing OpenAI's GPT-5 mini and Alibaba's Qwen3-VL across an average of 13 visual AI benchmarks. Despite having 33 billion parameters — roughly one-seventh the scale of the company's flagship K-EXAONE foundation model — EXAONE 4.5 achieves comparable reasoning performance.
Key Highlights:
In STEM benchmark evaluations across five metrics, EXAONE 4.5 recorded an average score of 77.3, outpacing GPT-5 mini (73.5), Anthropic's Claude Sonnet 4.5 (74.6), and Alibaba's Qwen3 235B (77.0). The model scored 81.4 on LiveCodeBench v6, edging out Google's latest Gemma 4 (80.0), and posted 62.2 on ChartQA Pro for complex chart analysis. LG attributed the efficiency gains to a proprietary hybrid attention architecture and in-house multi-token prediction technology for high-speed inference.
LG AI Research Lab positioned EXAONE 4.5 as the technical foundation for expanding its K-EXAONE project into multimodal capabilities, with physical intelligence — AI capable of perceiving and acting in the real world — cited as the long-term goal. The model has been released as open weights on Hugging Face for research, academic, and educational use, with official language support expanded to include Spanish, German, Japanese, and Vietnamese. Eajeong Lee, head of EXAONE Lab, said the company intends to extend the model's comprehension to audio, video, and physical environments, building AI that can "make real-world judgments and act in industrial settings."
EXAONE 4.5: Questions Readers Are Asking
Q: How does EXAONE 4.5 compare to other leading AI models?
A: Across an average of 13 visual AI benchmark metrics, EXAONE 4.5 outperformed OpenAI's GPT-5 mini, Anthropic's Claude Sonnet 4.5, and Alibaba's Qwen3-VL. It also surpassed Google's Gemma 4 on the LiveCodeBench v6 coding evaluation, demonstrating competitive strength in both visual reasoning and code generation.
Q: What does open weights mean, and is EXAONE 4.5 free to use?
A: Open weights refers to the public release of a trained AI model's parameters, allowing researchers and developers to build upon them freely. EXAONE 4.5 is available on Hugging Face at no cost for research, academic, and educational purposes. Commercial use is subject to separate licensing terms.
Q: What is physical intelligence, and why does it matter for EXAONE's roadmap?
A: Physical intelligence describes an AI's ability to go beyond digital tasks and operate in the real world — perceiving physical environments and driving robotic or physical systems. LG AI Research Lab is advancing EXAONE along a staged roadmap from text to multimodal to physical intelligence, with EXAONE 4.5 representing the multimodal milestone in that progression.
LG AI研究院发布多模态人工智能模型"EXAONE 4.5",13项视觉基准平均得分超越GPT-5 mini
首尔,4月9日——韩国LG AI研究院9日发布多模态人工智能模型"EXAONE 4.5",该模型能够同时理解和推理文本与图像信息,标志着LG正式迈入多模态AI时代。EXAONE 4.5将自主研发的视觉编码器与大语言模型(LLM)整合为统一架构,在13项视觉能力评估基准平均得分上超越OpenAI的GPT-5 mini及阿里巴巴的Qwen3-VL。该模型参数量为330亿(33B),约为LG旗舰基础模型"K-EXAONE"的七分之一,却实现了同等水平的推理性能。
核心要点:
在STEM性能评测的5项指标平均得分中,EXAONE 4.5以77.3分领先GPT-5 mini(73.5分)、Anthropic公司的Claude Sonnet 4.5(74.6分)及阿里巴巴Qwen3 235B(77.0分)。在编程能力基准测试LiveCodeBench v6中,该模型以81.4分超越谷歌Gemma 4(80.0分);在复杂图表分析评测ChartQA Pro中得分62.2分,展现出较强的全球竞争力。上述性能与效率的双重提升,源于LG自主研发的混合注意力架构与多令牌预测高速推理技术。
LG AI研究院将EXAONE 4.5定位为独立AI基础模型项目"K-EXAONE"实现多模态扩展的技术基础,并以实体智能(Physical Intelligence)作为长期发展目标。该模型已以开放权重形式在Hugging Face平台发布,可供研究、学术及教育用途使用,正式支持语言亦从韩语、英语扩展至西班牙语、德语、日语、越南语。EXAONE实验室负责人이진식表示,公司将持续扩展AI对语音、视频及物理环境的理解能力,"打造能够在工业场景中真正做出判断和行动的AI"。
关于EXAONE 4.5,您可能想了解的问题
Q:EXAONE 4.5与其他主流AI模型相比,优势体现在哪些方面?
A:在13项视觉能力评估基准的平均得分上,EXAONE 4.5超越了OpenAI的GPT-5 mini、Anthropic的Claude Sonnet 4.5以及阿里巴巴的Qwen3-VL;在编程基准LiveCodeBench v6中亦超越了谷歌Gemma 4,综合性能在同级模型中处于领先水平。
Q:"开放权重"是什么意思?普通用户可以免费使用吗?
A:"开放权重"是指公开发布AI模型经过训练的参数数值,使开发者可在此基础上进行研究与二次开发。EXAONE 4.5已在Hugging Face平台开放,支持研究、学术和教育目的的免费使用,商业用途须遵守相关许可条款。
Q:什么是"实体智能",它与EXAONE的发展路线有何关联?
A:实体智能(Physical Intelligence)是指AI突破虚拟数字环境的限制,能够感知物理世界并驱动机器人等实体设备做出行动的能力。LG AI研究院正推进EXAONE从文本理解、多模态感知到实体智能的阶段性演进路线,EXAONE 4.5是这一路线中多模态扩展阶段的核心成果。
LGがマルチモーダルAI「EXAONE 4.5」を公開 視覚評価13指標平均でGPT-5 miniを上回る
【ソウル 4月9日】LG AI研究院は9日、テキストと画像を同時に理解・推論するマルチモーダルAIモデル「EXAONE(エクサワン)4.5」を公開した。独自開発のビジョンエンコーダーと大規模言語モデル(LLM)を一体化したビジョン言語モデル(VLM)で、視覚AI能力評価指標13項目の平均スコアでOpenAIのGPT-5 miniと中国・アリババのQwen3-VLを上回った。パラメーター数330億(33B)と同社の基盤モデル「K-EXAONE」の約7分の1の規模ながら、同等水準の推論性能を実現したとしている。
主なポイント:
STEMパフォーマンス評価の5指標平均スコアは77.3点で、GPT-5 mini(73.5点)、AnthropicのClaude Sonnet 4.5(74.6点)、アリババのQwen3 235B(77.0点)をいずれも上回った。コーディングベンチマーク「LiveCodeBench v6」では81.4点を記録し、グーグルの最新モデルGemma 4(80.0点)を超えた。複雑なチャートの分析・推論能力を評価する「ChartQA Pro」では62.2点を獲得し、同クラスモデルとの比較でグローバル競争力を示した。
LG AI研究院は同モデルを、独自AI基盤モデル「K-EXAONE」のマルチモーダル拡張に向けた技術的土台と位置づけており、最終的には物理的な世界を理解・判断する「フィジカルインテリジェンス」の実現を目指す。EXAONE 4.5はオープンウェイトとしてHugging Faceで公開されており、研究・学術・教育目的での利用が可能で、公式サポート言語もスペイン語・ドイツ語・日本語・ベトナム語に拡張された。エクサワンラボ長のイ・ジンシク氏は「音声、映像、物理環境までAIの理解範囲を広げ、産業現場で実際に判断・行動できるAIを構築していく」と述べた。
EXAONE 4.5についてよくある疑問
Q:EXAONE 4.5は他の主要AIモデルと比べてどのような強みがありますか?
A:視覚AI能力評価の13指標平均スコアにおいて、OpenAIのGPT-5 mini、AnthropicのClaude Sonnet 4.5、アリババのQwen3-VLをすべて上回りました。またコーディングベンチマーク「LiveCodeBench v6」ではグーグルのGemma 4も超えており、マルチモーダルとコーディングの両分野でグローバルな競争力を示しています。
Q:「オープンウェイト」とはどういう意味で、誰でも利用できますか?
A:オープンウェイトとは、AIモデルの学習済みパラメーターを一般に公開することを指します。EXAONE 4.5はHugging Faceにて研究・学術・教育目的で無料公開されており、商業利用は別途ライセンス条件が適用されます。
Q:「フィジカルインテリジェンス」とは何ですか?EXAONEとの関係は?
A:フィジカルインテリジェンスとは、AIが仮想空間を超えて物理的な現実世界を認識・判断し、ロボットなどの実機を動かす能力を指します。LG AI研究院はEXAONEをテキスト→マルチモーダル→フィジカルインテリジェンスと段階的に発展させるロードマップを推進しており、EXAONE 4.5はそのマルチモーダル段階の中核となる成果です。
[Seoul = Techsuda eyeball@techsuda.com]

테크가 전 산업 영역에 스며드는 소식에 관심이 많다. 1999년 정보시대 PCWEEK 테크 전문지 기자로 입문한 후 월간 텔레닷컴, 인터넷 미디어 블로터닷넷 창간 멤버로 활동했다. 개발자 잡지 마이크로소프트웨어 편집장을 거쳐 테크수다를 창간해 지금까지 활동하고 있다. 태블릿을 가지고 얼굴이 꽉 찬 방송, 스마트폰을 활용한 현장 라이브를 한국 최초로 진행했다.